Face à une demande grandissante de disponibilité des données, le clustering s’impose comme une réponse adaptée pour l’hébergement de serveurs.
En tant qu’expert de l’hébergement cloud, nous vous accompagnons dans vos projets d’amélioration de la disponibilité de vos services. Nos équipes sont là pour vous aider à :
Afin de fournir une disponibilité optimale de vos services, il est possible d’utiliser le principe de mise en cluster pour l’hébergement de serveurs. Il existe 2 approches :
Le failover cluster (ou cluster à basculement) permet d’assurer la haute disponibilité d’un service. Il est souvent utilisé avec des technologies comme les serveurs SQL, la virtualisation, etc…
Le failover cluster se base sur un principe actif/passif. Vous disposez de différents nœuds (ex : serveurs) assurant tous le même service. Un nœud est élu master, il reçoit et traite les requêtes (transaction SQL, …). Les autres nœuds sont en attente, ils ne répondent pas aux requêtes.
En cas de défaillance du nœud master, le service est basculé sur un nœud passif, qui devient alors un nouveau master, pour continuer à traiter les requêtes.
Prenons l’exemple d’un cluster à basculement SQL. Le service fourni est donc une base de données. Dans un fonctionnement normal (partie de gauche), le serveur en bleu assume le rôle actif du cluster. C’est ce dernier qui répond aux requêtes de l’utilisateur. Le second serveur, en gris, est alors passif.
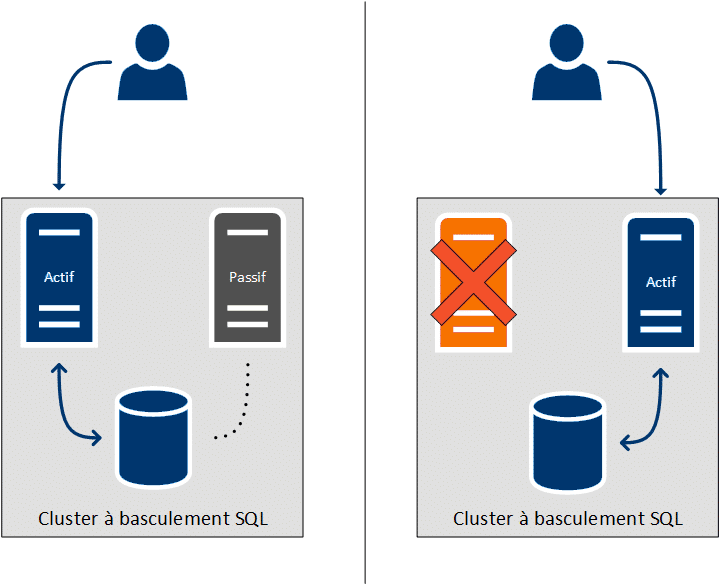
En cas de problème sur le serveur actif (partie de droite), le serveur anciennement passif détecte le problème et devient à son tour actif. Il prend alors en charge les requêtes de l’utilisateur.
Du côté utilisateur, la panne et le basculement ont été totalement transparent. L’utilisateur continue d’utiliser sa base de données sans avoir besoin de se connecter à un serveur différent.
Le principal inconvénient du failover clustering est le fait qu’il n’y ait qu’un nœud actif à un moment donné et donc aucune répartition de la charge. Il y a donc un gaspillage de ressources.

Cependant, il existe des services qui ne peuvent être rendus hautement disponibles qu’avec du failover clustering. Par exemple, les serveurs SQL utilisent des techniques pour vérifier et assurer la cohérence et l’intégrité des données qui rendent impossible l’utilisation de plusieurs nœuds actifs en même temps.
Une autre solution pour assurer la haute disponibilité d’un service ou d’une application serait de répartir la charge sur plusieurs nœuds. En effet, si une défaillance survient sur un nœud sa charge et redistribué sur les nœuds restants. On parle alors de fonctionnement actif/actif.
Les différents nœuds du cluster fournissent toujours le même service comme dans le cas du failover. Cependant dans ce cas, tous les nœuds peuvent répondre et traiter les requêtes. Plusieurs métriques peuvent être utilisées pour répartir la charge en fonction des besoins de l’applications : l’utilisation CPU, la quantité de RAM, l’adresse IP cliente, …
Le seul prérequis à l’utilisation de cette technologie est la compatibilité avec l’application que vous souhaitez rendre hautement disponible. Par exemple : les serveurs SQL ne supportent pas la répartition de charge, la haute-disponibilité est effectué grâce au failover clustering. Au contraire les services Web (site web, api) sont particulièrement adaptés au mode de fonctionnement du load-balancing.
Prenons le cas d’un site web. Les utilisateurs se connectent à un site web (ex : site eCommerce, évenementiel, médias, sportifs, live, direct). La charge est répartie sur plusieurs serveurs pour pouvoir encaisser un fort trafic.
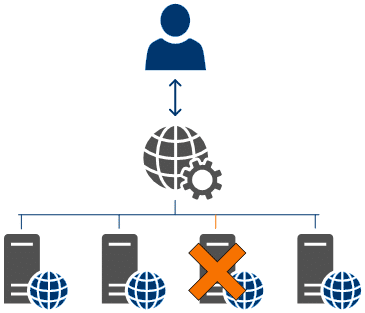
On constate que, même en cas de dysfonctionnement d’un serveur, le site web continue de fonctionner normalement. Le serveur non-fonctionnel ne participe plus au cluster et la charge est repartie sur les nœuds restants.
Le load-balancing, tout comme le failover clustering, permet d’assurer la haute-disponibilité d’un service donné. En plus de la haute-disponibilité, vous bénéficiez aussi de la répartition de charge, permettant une meilleure optimisation et rationalisation de vos ressources.
En effet, tous les nœuds travaillent de concert, vous n’avez pas de ressources en attente.
Lorsque cela est possible, il est préférable d’utiliser le mode de fonctionnement actif/actif. Vous bénéficiez de la haute-disponibilité ainsi que d’une répartition de charge. Vos ressources sont utilisées de manière optimale. De plus, l’évolutivité de votre solution est plus souple : il vous suffit de rajouter un nouveau nœud au cluster.
Au contraire dans le cas du failover clustering il vous faudrait augmenter les ressources physiques du serveur, une opération contraignante et généralement difficilement réversible.
Cependant, le failover clustering reste une solution adaptée, principalement lorsque le service n’est pas compatible avec le load-balancing (ex : serveurs SQL).

Le cloud expliqué simplement Aujourd’hui, pour les entreprises comme pour les particuliers, le cloud est devenu incontournable. Votre smartphone, votre adresse mail (personnelle et professionnelle), voire même vos objets connectés utilisent cette technologie sans parfois que vous vous en rendiez compte. Pourtant bien utilisée par tout un chacun, c’est une notion qui reste encore floue. Faisons le point […]
Lire la suite
Microsoft activera prochainement les paramètres de sécurité par défaut sur les tenants Office 365 jugés insuffisamment sécurisés. Il s’agit d’un ensemble de paramètres de sécurité qui visent à renforcer la protection de vos comptes et de votre organisation contre les attaques liées à l’identité, comme le spray de mots de passe, le rejeu et le [...]
Lire la suite
Azure Virtual Desktop (AVD) révolutionne l’utilisation des logiciels de CAO/DAO en entreprise. Cette solution cloud de Microsoft permet d’exécuter des applications gourmandes en ressources depuis n’importe quel appareil. Les professionnels peuvent désormais accéder à leurs logiciels métiers complexes tout en bénéficiant de performances optimales et d’une flexibilité accrue. Nous vous proposons un panorama pour découvrir […]
Lire la suite